- ออกแบบ Relation schema ที่ง่ายต่อการเข้าใจ่
- อย่ารวม attribute จาก multiple entity และ relationship type มากับ single relation
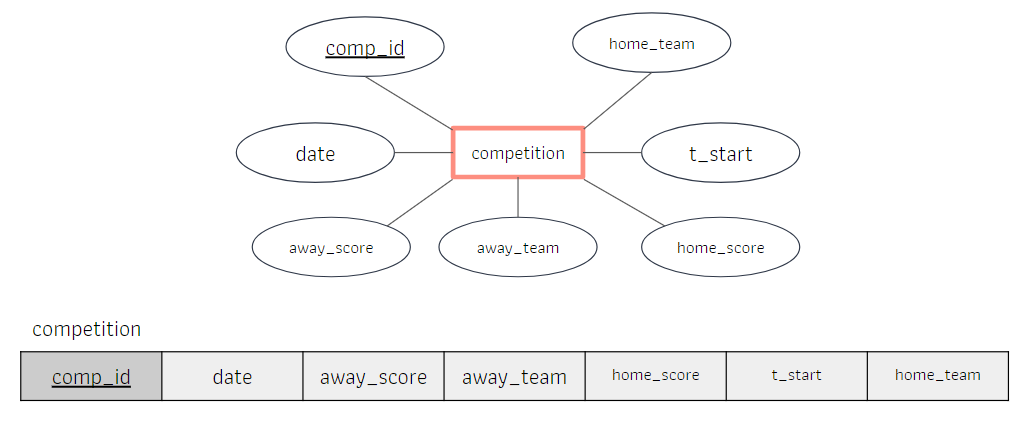
- จากภาพเป็นส่วนของ Employee ที่เพิ่ม Dname, Dmgr_ssn (เกิดจากการผสมของ distinct real-world entities ของ employees กับ department)


- มีข้อมูลที่ซ้ำกันใน EMP_DEPT ซึ่งส่งผลทำให้พื้นที่ในการจัดเก็บข้อมูล ซึ่งแก้โดยการ Update anomalies (EMPLOYEE x DEPARTMENT)

ชนิดของการ Update anomalies มี
- Insertion
- Deletion
- Modification
Insertion Anomalies
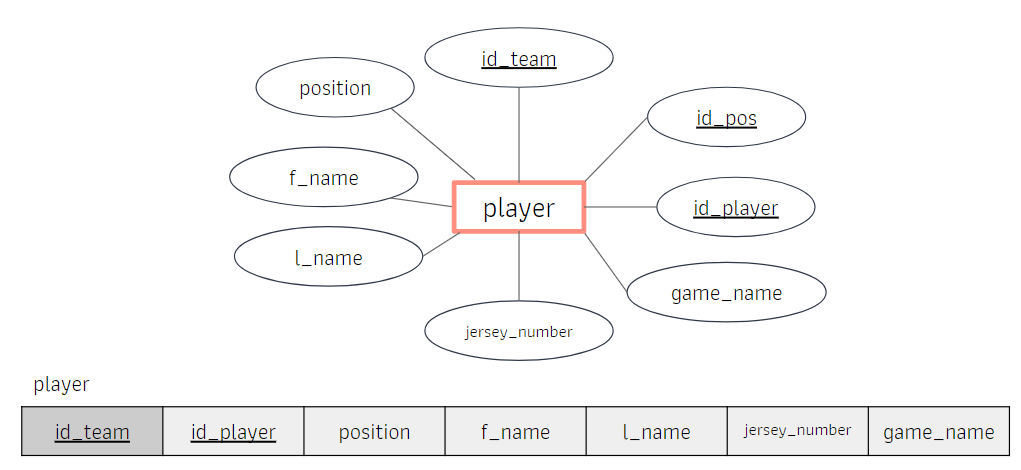
- เมื่อเพิ่ม tuple ใหม่ลงไปใน employee ที่ทำงานใน department มี Dnumber คือ 5 แล้ว attitbute value of department ทั้งหมดที่เป็น 5 เป็น consistent
- ถ้าลบ employee ที่อยู่ตัวสุดท้ายแล้ว ข้อมูลที่อยู่ department เดียวกันก็จะถูกลบด้วย เช่น หากลบ Borg แล้วจะลบ Headquarters ด้วย
Modification Anomalies
- หากเปลี่ยน manager ของ department 5 เราต้อง update ค่าใน tuple ของ employee ทั้งหมดที่ทำงานใน department นี้ แล้ว Database จะเปลี่ยนเป็น inconsistent
แนวทางที่ 2
- ออกแบบ base relation schema ที่ไม่มีการ update anomalies
- ถ้ามี anomalies (เพื่อเพิ่มประสิทธิภาพในการ query) ให้สังเกตและตรวจสอบให้แน่ใจว่าโปรแกรมนั้นมีการ Update ที่ถูกต้องหรือไม่
แนวทางที่ 3
- หลีกเลี่ยงการวาง Attribute ที่อยู่ใน base relation ซึ่งมีค่าส่วนใหญ่เป็น NULL
- หากหลีกเลี่ยงเกิด NULL ไม่ได้ ให้ Make sure ว่าใช้ในกรณีพิเศษเท่านั้น ไม่ใช้กับ tuple หลัก
- เช่น ถ้า 15% ของ employee เป็น individual offices => ให้ทำการสร้าง attribute ชื่อ Office_number ใน EMPLOYEE relation
แนวทางที่ 4
- การออกแบบ relation schema นั้นเราสามารถ join เงื่อนไขบน attribute ได้ตามความเหมาะสม (primary key, foreign key) ซึ่งการันตีได้ว่าไม่มี tuple นอกเงื่อนไขโผล่ขึ้นมา เพราะหากมีการหลีกเลี่ยง relation ที่มีการจับคู่ attribute ต่างๆ (foreign key, primary key) อาจทำให้เกิดการสร้าง Tuple นอกเงื่อนไขขึ้นมาได้